项目地址
dyh/win10_yolov5_deepsort_counting: 在 win10 运行 yolov5 deepsort 行人 车辆 跟踪 检测 计数 (github.com)
环境部署
首先先假设我们已经安装好了Anaconda,
然后再假设我们安装好了CUDA11.7,
最好再假设我们安装好了Pycharm,
首先我们先配置一下python3.9的虚拟环境:
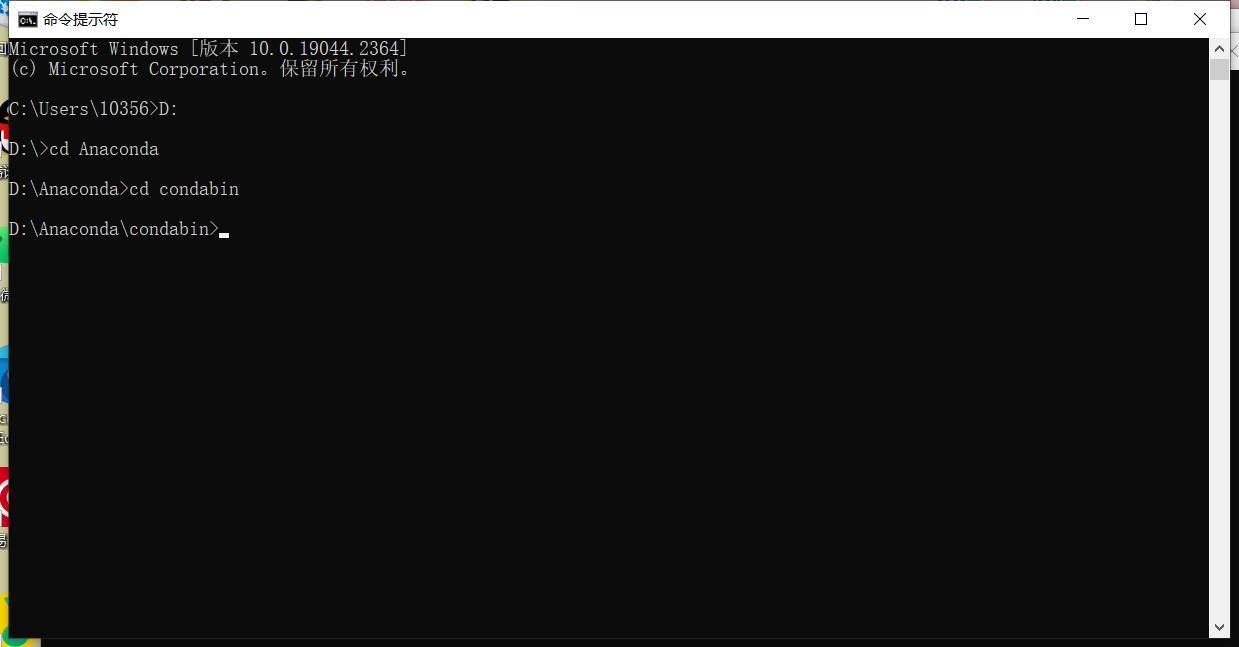
首先我们三步走进入condabin文件夹,Anaconda安装目录每个人可能不同。
接着输入conda create -n counting python=3.9
一路回车。
这样就创建完了,接下来激活虚拟环境,输入conda activate counting,输入后会在前面带有括号。
在项目文件夹中复制requirements文件到虚拟环境文件夹中,cmd进入虚拟环境文件夹。

接着输入pip3 install -r requirements.txt,安装项目外部库。
虚拟环境下输入python -m pip install —upgrade pip升级pip,接下来去Start Locally | PyTorch找到对应的安装命令,下载对应CUDA版本的Pytorch,因为我电脑环境配置了CUDA11.7,这里就不在虚拟环境配置CUDA了,默认都装好了,这里输入pip3 install torch torchvision torchaudio —extra-index-url https://download.pytorch.org/whl/cu117 。

打开项目文件夹,右键,选择打开文件夹作为Pycharm项目,并且信任项目。
选择配置好的虚拟环境作为Python解释器。
尝试运行一下。

出现了一个小报错,小修改,将from cv2 import cv2 改成import cv2即可。


再试试:

又有新报错,查查资料,打开upsampling.py,小做修改。


再试试:

能跑了,但是没有框框。
再看看,将detector.py里的model.half改成model.float,img.half改成img.float。


再试试:

有框框了。
接下来看看代码。
代码阅读
detector.py
init
# 初始化属性
def __init__(self):
self.img_size = 640 # 照片尺寸缩放
self.threshold = 0.3 # 置信度阈值
self.stride = 1 # 卷积步长
self.weights = './weights/yolov5m.pt' # 权重模型,采用yolov5官方权重
self.device = '0' if torch.cuda.is_available() else 'cpu' # 训练设备根据配置选择显卡或CPU
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device) # 导入模型权重,指定训练设备
model.to(self.device).eval()
model.float() # 模型数据类型改为float
self.m = model # 存放model方法
self.names = model.module.names if hasattr(
model, 'module') else model.names # 获得识别标签preprocess
def preprocess(self, img):
# 复制图像副本,浅复制
img0 = img.copy()
# yolov5图像预处理letterbox,等比缩放到img_size大小,不够的地方补充黑边
img = letterbox(img, new_shape=self.img_size)[0]
# 对于opencv读取的图像数据来说,储存格式为[B,G,R],B,G,R为色域比例
# img[:, :, ::-1]指:[B,G,R]翻转成[R,G,B]
# 我没特别理解这步的作用,因为貌似不进行颜色信道的翻转也能跑
# img[:, :, (2, 1, 0)]这样的操作同样可以实现翻转
# transpose(2, 0, 1)作用是将数据shape从(h,w,3)转变为(3,h,w),方便计算
img = img[:, :, ::-1].transpose(2, 0, 1)
# img进行处理后,作内存连续化
img = np.ascontiguousarray(img)
# 将img的numpy数组转变为tensor,两者共享内存,指定在显卡上
img = torch.from_numpy(img).to(self.device)
img = img.float()
# opencv采用的是256级RGB,即每个像素的RGB强度都为0-255的整数,这一步是归一重整
img /= 255.0
# 如果img张量的维度是3,则将其扩容,一个RGB图片总是三维的
# 扩充维度的原因估计是从一张图片的处理,变成对一堆图片的处理
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 返回原图和预处理后的图
return img0, img这一个方法可以写点东西。
img = letterbox(img, new_shape=self.img_size)[0]letterbox函数,深度学习模型输入图片的尺寸为正方形,而数据集中的图片一般为长方形,粗暴的resize会使得图片失真,采用letterbox可以较好的解决这个问题。该方法可以保持图片的长宽比例,剩下的部分采用灰色填充。

letterbox函数的返回的第一个量是图片的RGB张量。
img = img[:, :, ::-1].transpose(2, 0, 1)这一步是对图片RGB张量的处理。
一个空白的图像画布,比如2x2,可以理解成一个2x2的矩阵
RGB色彩就是通过红光Red,绿光Green,和蓝光Blue按照不同的亮度混合的,因此一种颜色可以通过一个RGB矢量表示:
我们假设有一个2*2像素的图片,通过opencv导入后,得到的img张量大概长这样(imread方法读取图片以BGR顺序返回图像数据):
是一个三维张量,shape:(2,2,3) (行像素数,列像素数,3),可以理解成是一个二维张量矩阵,但里面装的不是数,是RGB亮度矢量,因此是2+1=3维,这样做就可以得到一张图片色彩张量。
但是imshow方法要求的以RGB的顺序进行输入以重现图像。
因此先进行倒序:
img[:, :, ::-1]长这样:
这样的shape还是(2,2,3),我们经过:
.transpose(2, 0, 1)shape变成了(3,2,2),长这样:
可以理解成本来是一个shape=3的一维向量,但是里面放的不是数了,而是矩阵。
单独拎出来看,这是一个只有红光强度的单色图层:
这样整个张量就可以写成这个样子:
后面我们通过img.unsqueeze(0)进行升维度,结果长这样:
写成这样会更清晰:
再来一张照片的话就可以写成这样了:
这样就是两帧的色彩张量。
img = np.ascontiguousarray(img)这是内存连续化。
opencv将图片数据保存到img时,开辟了一组堆内存,在堆内存里保存数据,并把堆内存的操作地址给了图像数据img,这一操作地址存放在了栈内存。
但是对数据的翻转等操作改变了栈内存对堆内存的映射关系,并没有改变堆内存数据存放,因此此时内存存放看起来不连续了。
但是连续的内存运算起来更快,所以把堆内存的数据重新排放了一遍,这样就连续了。
detect
def detect(self, im):
# 获得原图和预处理后的图
im0, img = self.preprocess(im)
# 调用方法拿到model
# 根据github,augment是推理增强
# model本身是一个函数方法,self.m获得这个方法后进行运算,得到一堆预测坐标
pred = self.m(img, augment=False)[0]
pred = pred.float()
# NMS非极大值抑制,排除大部分预测坐标
pred = non_max_suppression(pred, self.threshold, 0.4)
# 空盒子
boxes = []
# 对pred中的所有数据
for det in pred:
# 如果pred不为空
if det is not None and len(det):
# 不同尺寸图片,坐标的映射改写
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im0.shape).round()
# 坐标,置信度,类别序号
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)] # 根据序号找到类别
if lbl not in ['person', 'bicycle', 'car', 'motorcycle', 'bus', 'truck']:
continue # 判断是否是这几个类别之一
pass
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
boxes.append(
(x1, y1, x2, y2, lbl, conf))
return boxes这里关键是scale_coords函数:
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()我们在前面把图像进行了缩放,缩放后再拿去跑模型检测,所以得到的坐标是缩放之后的图片坐标,但是我们希望得到原图的坐标,因此进行了这个函数。
tracker.py
config载入
cfg = get_config()
cfg.merge_from_file("./deep_sort/configs/deep_sort.yaml")
deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)这里引入了一个deepsort对象
draw_bboxes
def draw_bboxes(image, bboxes, line_thickness): # 画框框
line_thickness = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) * 0.5) + 1
# 线宽,要么指定,要么根据图像长宽像素算
list_pts = []
point_radius = 4 # 碰撞半径
for (x1, y1, x2, y2, cls_id, pos_id) in bboxes:
color = (0, 255, 0)
# 撞线的点
check_point_x = x1
check_point_y = int(y1 + ((y2 - y1) * 0.6))
c1, c2 = (x1, y1), (x2, y2) # c1是左上角,c2是右下角
# 用长方形的对角端点画框,框住检测出来的人的位置
cv2.rectangle(image, c1, c2, color, thickness=line_thickness, lineType=cv2.LINE_AA)
# 字符粗细
font_thickness = max(line_thickness - 1, 1)
t_size = cv2.getTextSize(cls_id, 0, fontScale=line_thickness / 3, thickness=font_thickness)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3 # 人框已经画完,现在将c2改为标签框的右上角,此时c1是标签框右下角
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # 填满一个长方形色块,作为标签颜色背景
cv2.putText(image, '{} ID-{}'.format(cls_id, pos_id), (c1[0], c1[1] - 2), 0, line_thickness / 3,
[225, 255, 255], thickness=font_thickness, lineType=cv2.LINE_AA) # 在色块上写字
# 定义碰撞带
list_pts.append([check_point_x - point_radius, check_point_y - point_radius])
list_pts.append([check_point_x - point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y - point_radius])
ndarray_pts = np.array(list_pts, np.int32)
# 人框上的红点
cv2.fillPoly(image, [ndarray_pts], color=(0, 0, 255))
# 清空
list_pts.clear()
return image首先看看几个opencv函数:
c1, c2 = (x1, y1), (x2, y2) # c1是左上角,c2是右下角
# 用长方形的对角端点画框,框住检测出来的人的位置
cv2.rectangle(image, c1, c2, color, thickness=line_thickness, lineType=cv2.LINE_AA)众所周知只需要两个点就能确定下一个矩形,c1和c2是模型检测出的人或物体所在的坐标,用c1和c2画框框就能把人给框起来,也就是下图的AB点,之后我们把c2坐标写在了C点,这样AC就可以画出标签框的颜色背景。

# 输入参数:要显示的字符,字体编号,字符比例,粗细
cv2.getTextSize(cls_id, 0, fontScale=line_thickness / 3, thickness=font_thickness)[0]
# 返回值(width,height),bottom
我们这里只取了(width,height),并没有取bottom。
cv2.fillPoly(image, [ndarray_pts], color=(0, 0, 255))update
def update(bboxes, image):
bbox_xywh = [] # x,y,长,宽
confs = [] # 置信度
bboxes2draw = [] # 待返回数据组
if len(bboxes) > 0:
for x1, y1, x2, y2, lbl, conf in bboxes:
obj = [
int((x1 + x2) * 0.5), int((y1 + y2) * 0.5),
x2 - x1, y2 - y1
] # 人框的中心坐标,以及方框长宽
bbox_xywh.append(obj)
confs.append(conf)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
# 下一步是目标跟踪,接收目标检测结果的矩形框坐标跑一遍deepsort
# deepsort会根据先前的帧确定目标检测结果的标识ID:track_id,即判断当前矩形框里的人和前一帧哪个矩形框里的人相同,相同就赋同一个id
outputs = deepsort.update(xywhs, confss, image)
for x1, y1, x2, y2, track_id in list(outputs):
center_x = (x1 + x2) * 0.5
center_y = (y1 + y2) * 0.5
# 但是经过deepsort的坐标因为经过一些处理,所以与之前的坐标有不同,所以通过一个search_label的函数寻找其标签
label = search_label(center_x=center_x, center_y=center_y, bboxes_xyxy=bboxes, max_dist_threshold=20.0)
bboxes2draw.append((x1, y1, x2, y2, label, track_id))
pass
pass
# 最终我们这个函数返回的:人框矩形坐标,标签,track_id
return bboxes2draw这里困难的是deepsort的理解,deepsort作为一个目标追踪的模块是比较方便的:
self.deepsort = DeepSort(args.deepsort_checkpoint) # 实例化
outputs = self.deepsort.update(bbox_xcycwh, cls_conf, im) #通过接收目标检测结果进行更新首先我们要经过一个目标检测模块,这里我们用的是yolov5,检测完后,会得到一堆的检测坐标,这些坐标其实就是上文说的人的矩形框对角坐标,把这堆坐标通过self.deepsort.update发给deepsort模块之后,deepsort会对这些矩形框进行序号标记,并且与下一帧进行对比。
当下一帧又发来一堆检测坐标的时候,deepsort会通过匈牙利算法判断两帧中哪两个矩形框框住的目标是同一个,然后给出框框的序号,这样我们的框框不仅跟着人走,还根据人的特征分发了序号,实现了目标追踪。
deepsort算法的具体内容另一篇写,这篇写不了那么多了。
search_label
def search_label(center_x, center_y, bboxes_xyxy, max_dist_threshold):
"""
在 yolov5 的 bbox 中搜索中心点最接近的label
:param center_x:
:param center_y:
:param bboxes_xyxy:
:param max_dist_threshold:
:return: 字符串
"""
label = ''
# min_label = ''
min_dist = -1.0
for x1, y1, x2, y2, lbl, conf in bboxes_xyxy:
center_x2 = (x1 + x2) * 0.5
center_y2 = (y1 + y2) * 0.5
# 横纵距离都小于 max_dist
min_x = abs(center_x2 - center_x)
min_y = abs(center_y2 - center_y)
if min_x < max_dist_threshold and min_y < max_dist_threshold:
# 距离阈值,判断是否在允许误差范围内
# 取 x, y 方向上的距离平均值
avg_dist = (min_x + min_y) * 0.5
if min_dist == -1.0:
# 第一次赋值
min_dist = avg_dist
# 赋值label
label = lbl
pass
else:
# 若不是第一次,则距离小的优先
if avg_dist < min_dist:
min_dist = avg_dist
# label
label = lbl
pass
pass
pass
return label这一个函数是因为,我们在拿到deepsort返回的矩形框坐标的时候,实际上跟我们发送过去的矩形框坐标有一点出入,但只相差几个像素,所以我们完全可以根据像素距离确定框框坐标的对应关系。
很容易看懂,就是把deepsort的矩形框中心坐标发进去,然后跟yolov5检测出的所有框框中心坐标对比,看跟哪个最近,把最近那个框框的标签取下来返回就行,看得懂python就能看得懂这段。
main.py
if __name__ == '__main__':
# 背景幕布,一个1080*1920的零矩阵,二维张量
mask_image_temp = np.zeros((1080, 1920), dtype=np.uint8)
# 蓝色撞线带
list_pts_blue = [[204, 305], [227, 431], [605, 522], [1101, 464], [1900, 601], [1902, 495], [1125, 379], [604, 437],
[299, 375], [267, 289]]
ndarray_pts_blue = np.array(list_pts_blue, np.int32)
polygon_blue_value_1 = cv2.fillPoly(mask_image_temp, [ndarray_pts_blue], color=1)
# 色彩通带升维度,由原来的1080*1920的矩阵,升成三维张量,1080*1920的矩阵上放的不再是数而是RGB向量
polygon_blue_value_1 = polygon_blue_value_1[:, :, np.newaxis]
# 填充第二个多边形撞线带
mask_image_temp = np.zeros((1080, 1920), dtype=np.uint8)
list_pts_yellow = [[181, 305], [207, 442], [603, 544], [1107, 485], [1898, 625], [1893, 701], [1101, 568],
[594, 637], [118, 483], [109, 303]]
ndarray_pts_yellow = np.array(list_pts_yellow, np.int32)
polygon_yellow_value_2 = cv2.fillPoly(mask_image_temp, [ndarray_pts_yellow], color=2)
polygon_yellow_value_2 = polygon_yellow_value_2[:, :, np.newaxis]
# 撞线检测用mask,包含2个polygon,(值范围 0、1、2),供撞线计算使用
# mask上,值0像素无碰撞检测,值1蓝色检测,值2黄色检测
polygon_mask_blue_and_yellow = polygon_blue_value_1 + polygon_yellow_value_2
# 缩小尺寸,1920x1080->960x540
polygon_mask_blue_and_yellow = cv2.resize(polygon_mask_blue_and_yellow, (960, 540))
# 蓝 色盘 b,g,r
blue_color_plate = [255, 0, 0]
# 蓝 polygon图片
blue_image = np.array(polygon_blue_value_1 * blue_color_plate, np.uint8)
# 黄 色盘
yellow_color_plate = [0, 255, 255]
# 黄 polygon图片
yellow_image = np.array(polygon_yellow_value_2 * yellow_color_plate, np.uint8)
# 彩色图片(值范围 0-255)
color_polygons_image = blue_image + yellow_image
# 缩小尺寸,1920x1080->960x540
color_polygons_image = cv2.resize(color_polygons_image, (960, 540))
# list 与蓝色polygon重叠
list_overlapping_blue_polygon = []
# list 与黄色polygon重叠
list_overlapping_yellow_polygon = []
# 进入数量
down_count = 0
# 离开数量
up_count = 0
# 设置字体类型
font_draw_number = cv2.FONT_HERSHEY_SIMPLEX
# 设置字体位置
draw_text_postion = (int(960 * 0.01), int(540 * 0.05))
# 初始化 yolov5
detector = Detector()
# 打开视频
capture = cv2.VideoCapture(r'video\test.mp4')
# 视频帧读取
while True:
# 读取每帧图片
_, im = capture.read()
# 没读取出图片即视频结束,break循环
if im is None:
break
# 缩小尺寸,1920x1080->960x540
im = cv2.resize(im, (960, 540))
# 初始化空列表bboxs
list_bboxs = []
# 将缩小后的图片交给detector对象进行探测
# 返回值(x1, y1, x2, y2, lbl, conf)
bboxes = detector.detect(im)
# 如果画面中有bbox,即detector探测到待检测对象
if len(bboxes) > 0:
# 我们就把detector探测到的坐标发给tracker,把图片update到跟踪器
list_bboxs = tracker.update(bboxes, im)
# 画框
# 画撞线检测点,(x1,y1 + ((y2 - y1) * 0.6),并且将图片返回(当前取了0.6为偏移量,在tracker.py30行)
output_image_frame = tracker.draw_bboxes(im, list_bboxs, line_thickness=None)
pass # 空命令,类似C里的分号
else:
# 如果画面中没有bbox,直接返回图片
output_image_frame = im
pass
# 输出图片
output_image_frame = cv2.add(output_image_frame, color_polygons_image)
if len(list_bboxs) > 0:
# ----------------------判断撞线----------------------
for item_bbox in list_bboxs:
x1, y1, x2, y2, label, track_id = item_bbox
# 撞线检测点,(x1,y1),y方向偏移比例 0.0~1.0
y1_offset = int(y1 + ((y2 - y1) * 0.6))
# 撞线的点
y = y1_offset
x = x1
if polygon_mask_blue_and_yellow[y, x] == 1:
# 如果撞蓝碰撞带,而且该检测点所属id未被记录,则记录
if track_id not in list_overlapping_blue_polygon:
list_overlapping_blue_polygon.append(track_id)
pass
# 判断 黄碰撞带 list 里是否有此 track_id
# 有此 track_id,则 认为是 外出方向
if track_id in list_overlapping_yellow_polygon:
# 外出+1
up_count += 1
print(
f'类别: {label} | id: {track_id} | 上行撞线 | 上行撞线总数: {up_count} | 上行id列表: {list_overlapping_yellow_polygon}')
# 删除 黄polygon list 中的此id
list_overlapping_yellow_polygon.remove(track_id)
pass
else:
# 无此 track_id,不做其他操作
pass
elif polygon_mask_blue_and_yellow[y, x] == 2:
# 如果撞黄碰撞带,而且该检测点所属id未被记录,则记录
if track_id not in list_overlapping_yellow_polygon:
list_overlapping_yellow_polygon.append(track_id)
pass
# 判断蓝碰撞带 list 里是否有此 track_id
# 有此 track_id,则 认为是 进入方向
if track_id in list_overlapping_blue_polygon:
# 进入+1
down_count += 1
print(
f'类别: {label} | id: {track_id} | 下行撞线 | 下行撞线总数: {down_count} | 下行id列表: {list_overlapping_blue_polygon}')
# 删除 蓝polygon list 中的此id
list_overlapping_blue_polygon.remove(track_id)
pass
else:
# 无此 track_id,不做其他操作
pass
pass
else:
pass
pass
pass
# ----------------------清除无用id----------------------
# 先把所有在碰撞带的id拼一起
list_overlapping_all = list_overlapping_yellow_polygon + list_overlapping_blue_polygon
# 查查看这些经过碰撞带的id是不是都在这帧被yolo和deepsort检测到
for id1 in list_overlapping_all:
is_found = False
for _, _, _, _, _, bbox_id in list_bboxs:
if bbox_id == id1:
is_found = True
break
pass
pass
if not is_found:
# 如果没找到,删除id
if id1 in list_overlapping_yellow_polygon:
list_overlapping_yellow_polygon.remove(id1)
pass
if id1 in list_overlapping_blue_polygon:
list_overlapping_blue_polygon.remove(id1)
pass
pass
list_overlapping_all.clear()
pass
# ----------------------清除无用id结束----------------------
# 清空list
list_bboxs.clear()
pass
else:
# 如果图像中没有任何的bbox,则清空list
list_overlapping_blue_polygon.clear()
list_overlapping_yellow_polygon.clear()
pass
pass
# 进出人数统计显示文本
text_draw = 'DOWN: ' + str(down_count) + \
' , UP: ' + str(up_count)
# 文本放在画面上
output_image_frame = cv2.putText(img=output_image_frame, text=text_draw,
org=draw_text_postion,
fontFace=font_draw_number,
fontScale=1, color=(255, 255, 255), thickness=2)
# 播放
cv2.imshow('demo', output_image_frame)
cv2.waitKey(1)
pass
pass
# 释放内存
capture.release()
# 关闭窗口
cv2.destroyAllWindows()个人觉得已经写得挺清晰了,跑一遍程序看看:
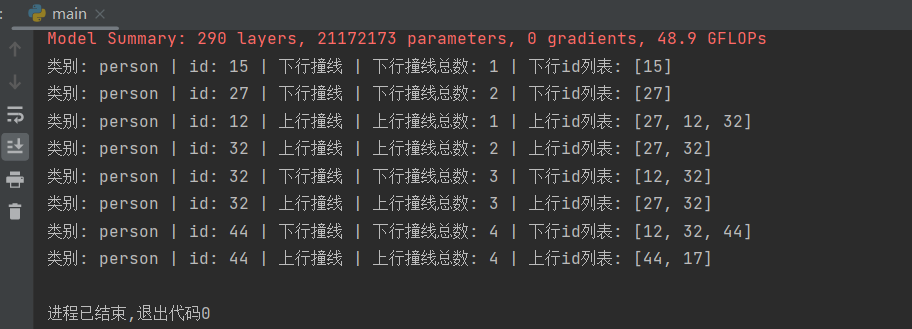
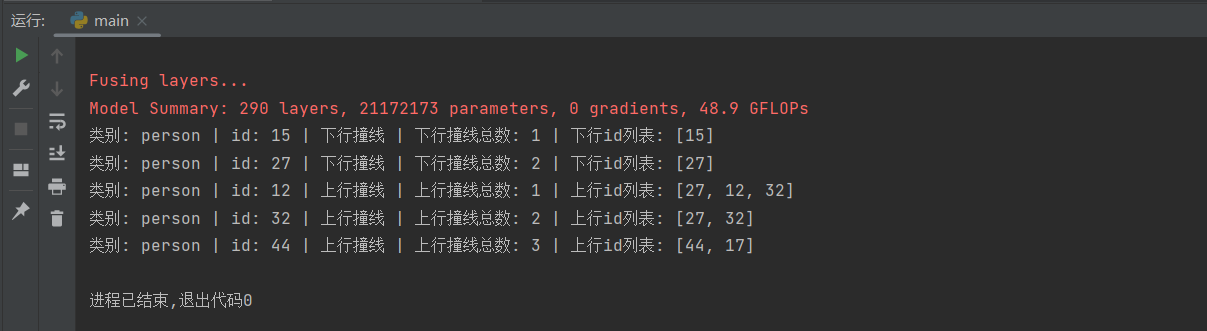
我们会发现这个id:32的person一共上行撞线了两次,下行撞线了一次,显然这里有碰撞带比较靠近,碰撞点抖动导致的问题,但是也不应该出现两次上行的检测。
我们重新看一下代码,判断上下行是通过蓝黄碰撞带实现的,进出的时候记录下他们碰撞带碰撞的先后顺序,先蓝后黄则下,先黄后蓝则上,如果视频里没有捣乱的人,那么每个人都只会碰撞到一次蓝带和一次黄带。
比如有人先经过蓝带,此时我们在蓝带碰撞列表中记下他的id,再经过黄带,此时我们在黄带碰撞列表中记下他的id,此时是先蓝后黄,所以是下行,我们下行总数加1,但是他还在黄带上,所以要把蓝带碰撞列表的id删掉,否则就会重复加1,因为我们认为蓝带是不会重复碰撞的。
但是实际不是这样的,首先我们这个目标检测还不足够精准,撞点会出现小范围的抖动,其次碰撞带相隔太短,小抖动就会导致从蓝带跑到黄带。
我们有两种方法解决:
第一种是,我们重新改一下碰撞带,让他们之间距离大一点,保证撞点的小范围抖动不会出现从蓝带跑到黄带的判定。
第二种是,我们的碰撞带足够宽,即便撞点有小范围的抖动,我们仍然能够保证撞点第一个撞到的碰撞带是正确的。
我们可以定义一个新的列表记录已经检测过上下行判断的id:
list_id_overlapping = []并把if部分小加一些内容
if track_id in list_overlapping_blue_polygon and track_id not in list_id_overlapping:
# 进入+1
down_count += 1
list_id_overlapping.append(track_id)if track_id in list_overlapping_yellow_polygon and track_id not in list_id_overlapping:
# 外出+1
up_count += 1
list_id_overlapping.append(track_id)我们再跑一遍:
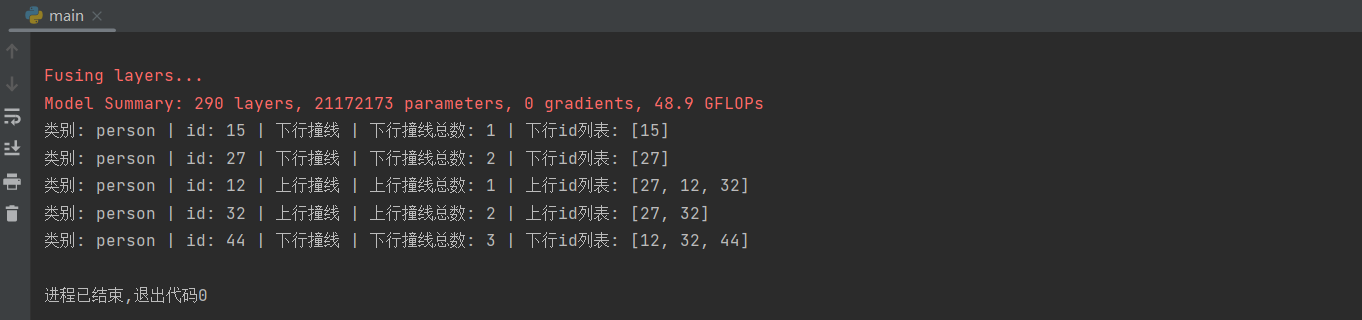
但是根据视频,44号应该是上行,我们在44号第一次被记录的时候设置一个breakpoint,把那帧图片用imwrite保存下来看看:
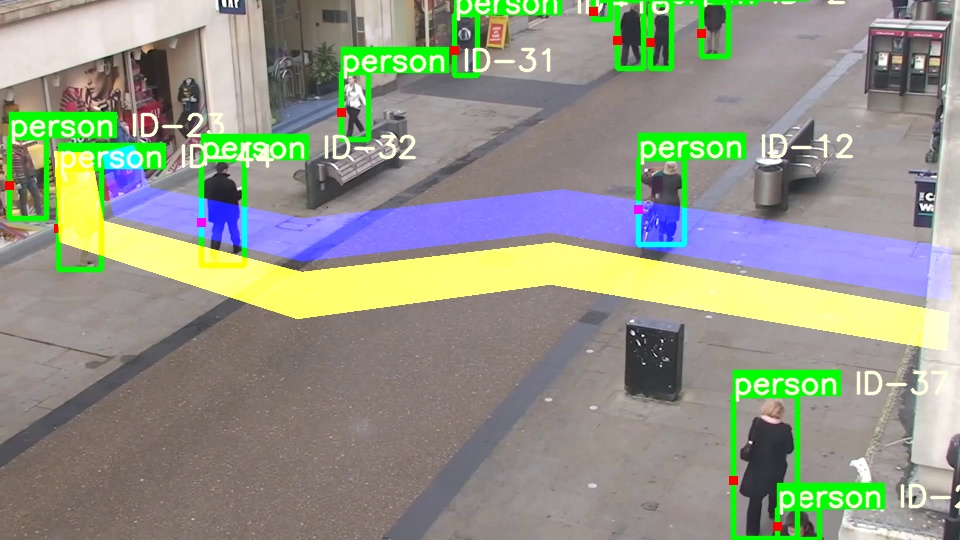
至少在我看来应该是碰到黄色才对,但是程序记录他碰到蓝色了…
再看看碰撞点坐标:
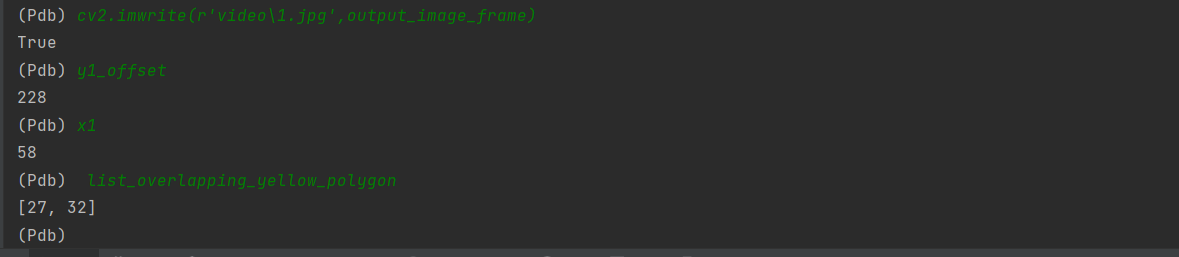
是(58,228),放去gimp查看像素:
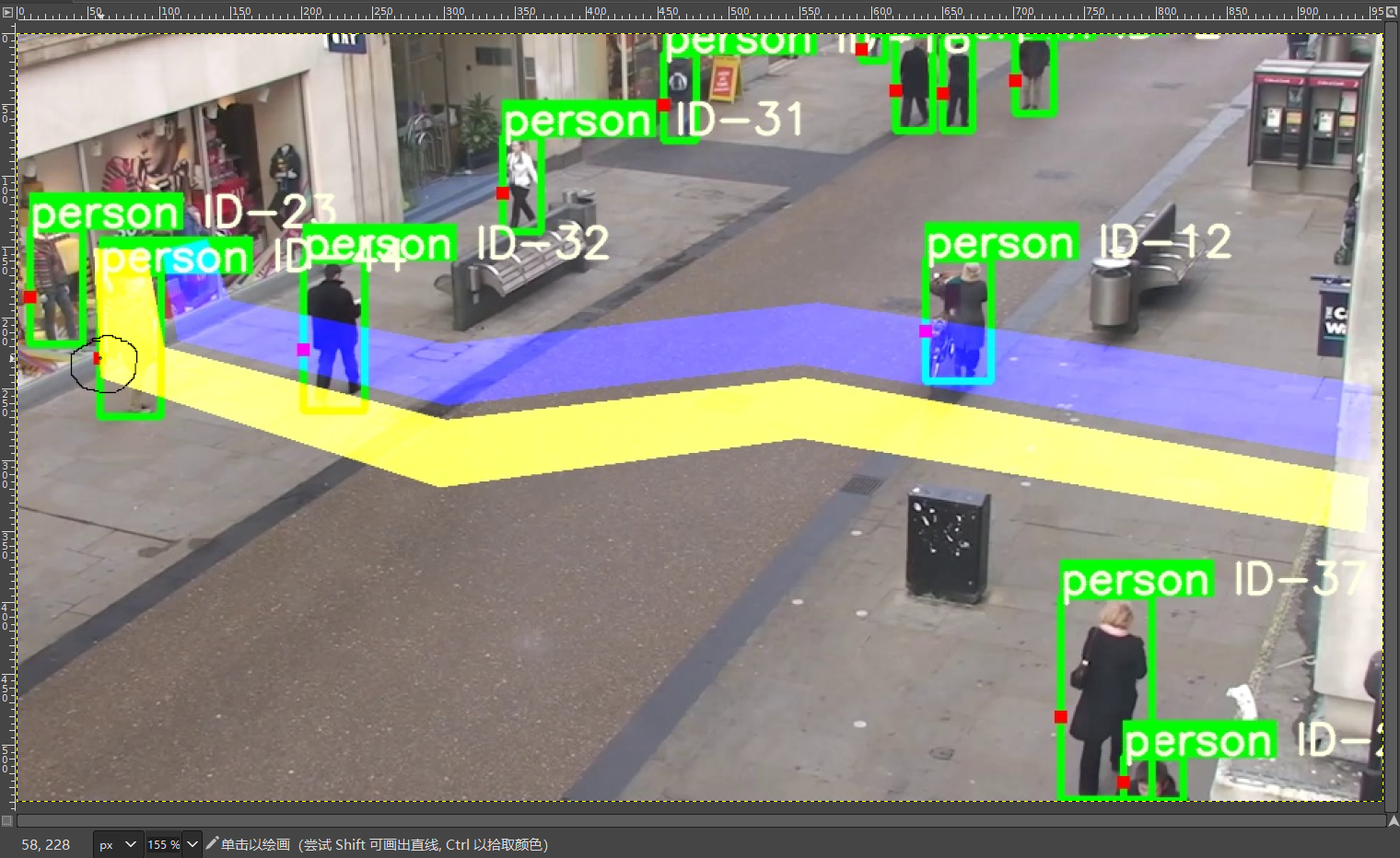
圈住的点应该刚好就是(58,228),也应该就是黄色碰撞带才对,看看附近的点值。
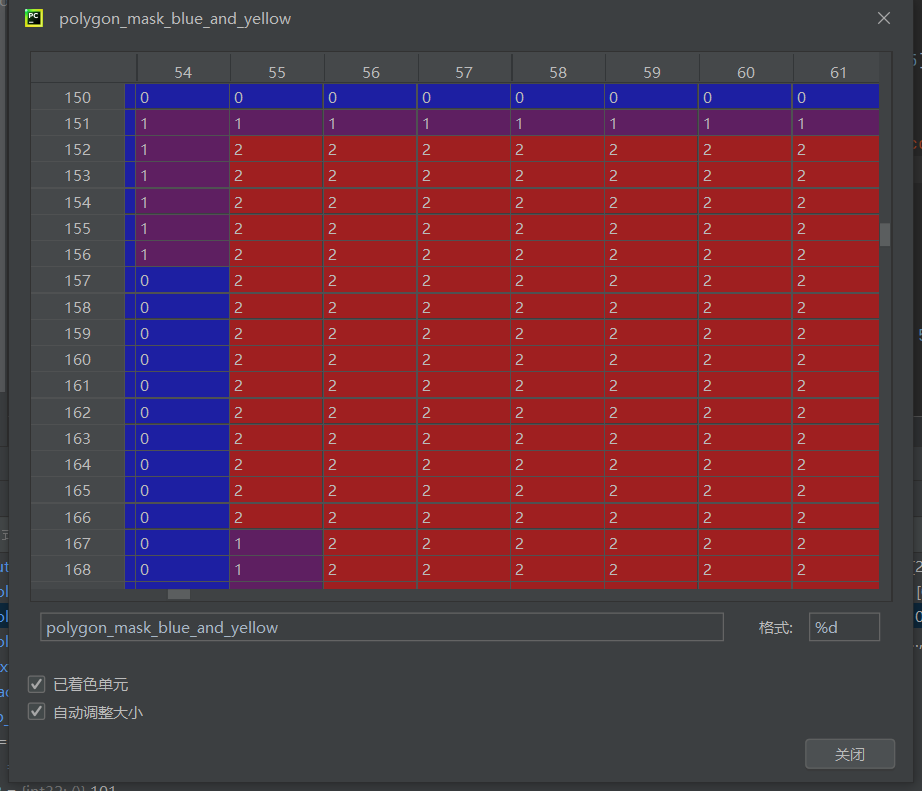
(0是幕布,1是蓝色碰撞带,2是黄色碰撞带)突然多了几行边界的1,可能是定义的时候出了问题,也可能是opencv转换的时候出了问题,先看看未转换前的色值:
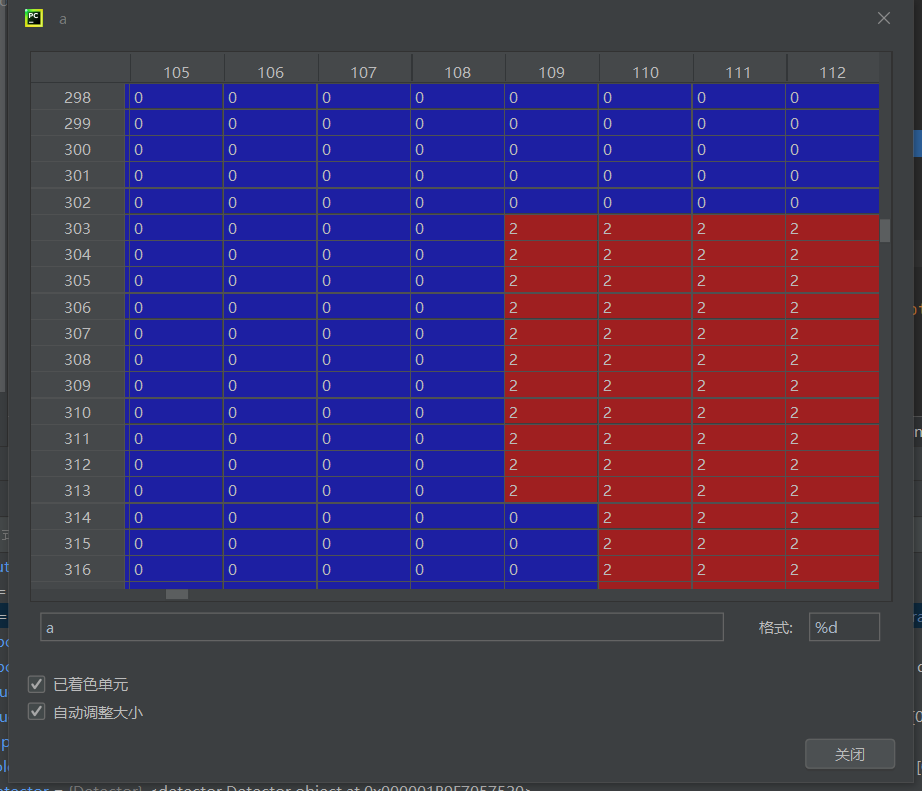
确实是因为opencv的转换导致的,我推测这里应该是转换的时候把部分边界作了均值处理,我们把2改成3看看会不会有所变化.
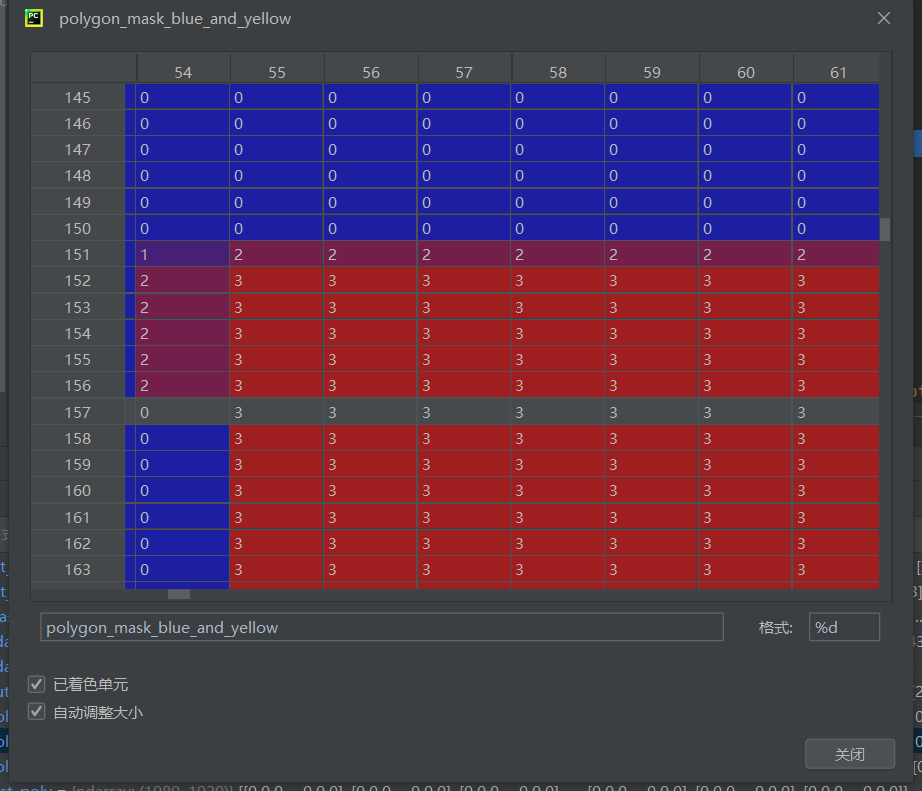
这应该是作了些均值处理,我们把它取成10,估计均值处理就不会出现1了,代码已经讲得比较清楚了,这部分的修改就不重新放上去了。
现在结果应该就对了:
yolo模型和deepsort算法分另外两篇发,项目工程架构到这里写完了。



